OmegaT, itzulpenak egiteko CAT aplikazio librea
Artikulua PDFn
CAT (Computer Aided Translation) aplikazioak ez dira iritsi berriak itzultzaileen mundura. Gero eta gehiagok erabiltzen dituzte TRADOS edo Wordfast bezalako tresnak. Badaude hain ezagunak ez diren aplikazioak ere, eta horien artean beharbada berezienetako bat OmegaT da. Berezia, kode irekiko software librea delako eta, beraz, mota honetako proiektu batek dituen abantailak eta eragozpenak dituelako.
Norbaitek oraindik ez badaki nola funtzionatzen duten CAT aplikazioek, hemen doa azalpen labur bat. CAT tresnak ez dira itzulpenak bere kabuz egiten dituzten aplikazio horien modukoak; horren ordez, testu zatiak eta beren itzulpenak «itzulpen memoria» deitzen den fitxategi batean gordetzen dituzte. Testu zati bat («segmentu» bat) hautatzen denean, aplikazioak itzulpen memoria aztertzen du, ea haren parekorik jada itzuli den ikusteko. Parekoak beste leiho batean erakusten ditu, eta nahi izanez gero, haietako bat hauta daiteke segmentuaren itzulpen gisa erabiltzeko.
OmegaT-k ere horrela funtzionatzen du. Beste CAT aplikazio batzuetan bezala, parekatzeak bi motatakoak izan daitezke: zehatzak edo lausoak. Parekatze lausoetan hitz guztiak ez datoz bat jatorrizko esaldian eta parekatzean, baina kasu askotan oso lagungarriak dira itzulpenaren fluxua azkartzeko eta testuaren homogeneotasuna handitzeko. OmegaT-k itzulgai den segmentuan eta parekatzean dauden hitz berdinen ehunekoak zenbatzen ditu, eta ehuneko jakin batetik gora dauden parekatzeak erakusten ditu. Mota honetako aplikazioetan normala denez, OmegaT-k darabiltzan itzulpen memoriak gero eta osatuagoak egon, ezaugarri hau erabilgarriagoa izango da.
OmegaT-k TMX formatuko itzulpen memoriak erabiltzen ditu eta, beraz, erraza da beste aplikazio batzuekin sortutako TMX-z baliatzea eta itzulpen memoriok beste erabiltzaile batzuekin partekatzea. OmegaT-k nahi adina TMX erabil dezake itzulpen proiektu batean.
OmegaT-ren abantailak
OmegaT-ri beste aplikazio batzuek dauzkaten zenbait lanabes aurreratu falta zaizkio, baina badauzka itzultzaileon arreta merezi duten beste hainbat ezaugarri bikain:
- Java izeneko plataformaren gainean eraiki da. Honek, praktikan, esan nahi du edozein sistema eragiletan erabil daitekeela: Windows, Mac, Linux...
- Itzulpen memoria bat baino gehiago kudea dezake proiektu berean. Hortaz, oso erraza da hainbat itzulpen memoriarekin lan egitea.
- Aplikazio autonomoa da, alegia, ez da Word (ez beste edozein aplikazio osagarririk) eduki beharrik itzulpenak egiteko.
- GPL lizentzia pean banatzen da. GPL software libreko lizentzia bat da, eta aplikazioak inolako mugarik gabe banatzea eta aldatzea baimentzen du.
- Laster euskaraz erabili ahal izango da.
Nola erabili OmegaT
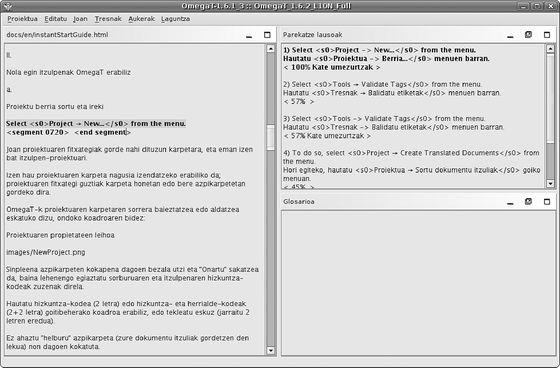
OmegaT irekitzen denean, hiru panelez osaturik dagoela ikus daiteke (ikus 1. irudia). Ezkerrean ageri den panela editorea da, hau da, itzulpena sartu eta editatzen den lekua. Eskuinean beste bi panelak ageri dira: goian parekatzeen bisorea, itzulpen memorietatik erauzitako segmentu antzekoenak erakusten diren lekua, eta behean glosarioen bisorea, glosario fitxategietan gorderik dagoen terminologia eta bere itzulpena erakusten dituena.
OmegaT-ren lan unitatea ez da fitxategia, proiektua baizik. Fitxategi bakar baten gainean lan egiten ez duenez, badu abantaila bat: formatu askotan dauden hainbat dokumentu aldi berean itzul daitezke, glosario eta itzulpen memoria berak erabiliz. Aplikazioak karpeta bat sortzen du ordenagailuan, eta horren barruan hainbat azpikarpeta, bat sorburu fitxategiak (alegia, itzuli behar diren dokumentuak) uzteko, beste bat glosarioak gordetzeko, beste bat sortuko diren itzulpen memoriak gordetzeko eta beste bat helburu fitxategiak (dokumentu itzuliak) gordetzeko.
Lanari ekiteko, jatorrizko dokumentuak proiektuaren source azpikarpetan kopiatzen dira. Beste lan batzuetan sortu diren itzulpen memoriak eta glosarioak ere balia daitezke, haiei dagozkien azpikarpetetan kokatuz. Hala ere, azken hauek ez dira zertan azpikarpeta horietan kokatu behar, eta posible da beste direktorio batzuetan edukitzea, proiektu guztietarako baliagarria izango den biltegi zentralizatu bat sortuz.
Proiektuari sorburu dokumentuak, itzulpen memoriak edo glosario berriak erants dakizkioke edozein unetan. Kasu horretan, nahikoa da proiektua «birkargatzea» OmegaT-k aldaketak kontuan har ditzan. Era berean, itzulpenaren erdian segmentazio arauak (beherago azalduko direnak) aldatzen badira, proiektua birkargatu egin behar da.
1. irudia: OmegaT-ren leiho nagusia
Proiektu bat ireki bezain laster, aplikazioak proiektuaren fitxategi guztien zerrenda erakutsiko du (ikus 2. irudia). Fitxategi hauek sorburu fitxategien azpikarpetan daudenak dira, baina ez denak, soilik OmegaT-k kudea ditzakeen formatua dutenak. Edozein fitxategiren izenean klikatzean, fitxategia editore panelean irekiko da eta itzultzeko prest geratuko da. Honez gain, leiho honek fitxategi bakoitzaren segmentu kopurua ere erakusten du, bai eta proiektu osoak daukan segmentu bakarren kopurua eta jada itzulita dauden segmentuen kopurua ere. Datu hauek segmentu bat itzultzen den bakoitzean eguneratzen dira.
OmegaT-k hainbat motatako fitxategiak onartzen ditu: testu hutsa, HTML, XHTML, StarOffice eta OpenOffice... Ez ditu Microsoft Office-ko dokumentuak (DOC, XLS, PPT) zuzenean onartzen; horiek itzuli nahi izanez gero, fitxategiak lehenbizi OpenOffice erabiliz ireki eta OpenDocument formatura bihurtzen dira, ondoren itzulpena egin eta berriro jatorrizko formatuan jartzen dira.
Glosarioei dagokienez, OmegaT-k tabuladorez mugatutako testu hutseko fitxategiak erabiltzen ditu. Fitxategi hauek oso sinpleak dira: lehen zutabean sorburu hizkuntzako hitza gordetzen du eta bigarren zutabe batean helburu hizkuntzakoa.
2. irudia: OmegaT-rekin kudeatutako proeiktu baten fitxategiak

Glosarioen panelak uneko segmentuan aurkitutako terminoen itzulpenak erakusten ditu, baina erreferentzia gisa soilik, ez baitu onartzen termino berriak eta beren itzulpena txertatzea edo existitzen diren terminoak ordeztea. OmegaT-k hitz anitzeko terminoak onartzen ditu, baina oso azaletik: termino baten bi hitzak uneko segmentuan badaude, terminoa panelean erakusten da.
Segmentazio arauak
Testu bat segmentatzeko hainbat modu dago. OmegaT-k, hasteko, testua egitura mailan segmentatzen du. Prozesu honetan zehar, sorburu fitxategiaren egitura erabiltzen da segmentuak sortzeko. Esaterako, testu fitxategiak segmentatzeko lerro jauziak, lerro hutsak eta antzekoak erabiltzen dira.
OmegaT-k esaldiz esaldi ere egin dezake segmentazioa. Esaldien segmentazioa egitura mailako segmentazioaren ondoren gauzatzen da. Zoritxarrez, prozesu hauetan sortutako segmentuak ezin dira aldatu (zatitu edo batu) itzulpena egiten ari den bitartean. Segmentazioa ez bada itzultzailearen gustukoa, sorburu fitxategia OmegaT-tik kanpo aldatu behar da edota esaldien segmentazio arauak aldatu behar dira.
OmegaT-k esaldiak segmentatzeko bi arau mota dauzka: eten-arauak, testua segmentuetan banatzen dutenak, eta salbuespen-arauak, banatu behar ez diren testu-zatiak zehazten dituztenak. Esaterako, «Nondik zatoz? Eskolatik.» perpausa bi segmentutan banatu daiteke «?» ikurraren ondoren eta, beraz, komenigarria litzateke eten-arau bat egongo balitz «?» ikurrerako. «Who is afraid of Mrs. Woolf?» ingelesezko esaldia, berriz, ez da segmentatu behar puntuaren ondoren eta, beraz, salbuespen-arau bat egon beharko litzateke «Mrs.» ikurrerako.
Batzuetan, hizkuntza bakoitzak segmentazio arau bereiziak behar izaten ditu. OmegaT-k aurretiaz definiturik dakartza hainbat hizkuntzatarako zenbait segmentazio arau (ikus 3. irudia). Eten arauei dagokienez, arau hauek aski izan beharko lukete Europako hizkuntza gehienetarako; salbuespen arauetarako, berriz, gomendagarria da itzulpenaren sorburu hizkuntzarako arau gehiago definitzea.
3. irudia: Segmentazioaren konfigurazioa OmegaT-n
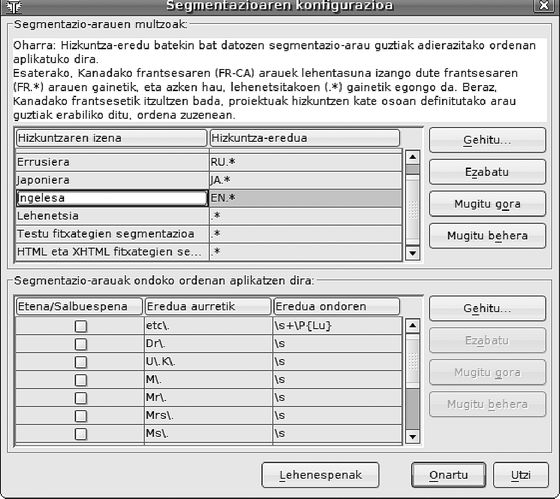
Hizkuntza bati dagozkion segmentazio arauen multzoak hizkuntzaren lehentasun ordenan aplikatzen dira, alegia, hizkuntza espezifikoetarako arauak lehenetsitako hizkuntzetarako arauen gainetik egongo dira. Esaterako, Kanadako frantsesaren (FR-CA) arauek lehentasuna izango dute frantsesaren (FR.&asterisk;) arauen gainetik, eta azken hauek, lehenetsitako arauen (.&asterisk;) gainetik egongo dira. Beraz, Kanadako frantsesetik itzultzen bada, proiektuak hizkuntza horretarako definitutako arauak, frantseserako definitutakoak eta lehenetsitakoak erabiliko ditu, ordena horretan.
Parekatzeen txertatzea
Itzulpena egiteko, kurtsorea segmentu batetik beste batera mugitzen da eta segmentu bakarra editatzen da aldi bakoitzean. Itzuli gabe dagoen segmentu batera mugitzean, itzultzaileak aurretiaz definitutako aukerak erabiltzen dira segmentuaren edizio eremua betetzeko. Aukera hauek Editatu portaera koadroan definitzen dira (ikus 4. irudia).
4. irudia: Partekatzeak txertatzeko aukerak
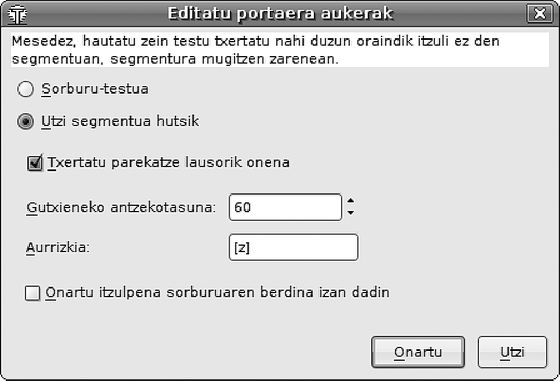
OmegaT-k, automatikoki, sorburu testuarekin bete dezake edizio eremua. Hau oso erabilgarria da ukitu gabe utzi behar diren izen berezi edo ikur asko dituen testua itzultzean.
Beste aukera bat edizio eremua hutsik uztea da. Aukera honi esker, ez dago sorburu testua kendu beharrik itzulpena egiteko eta tekla sakatze pare bat aurrezten da.
Azkenik, OmegaT-k antzekoena den parekatzea erabil dezake esaldiaren edizio eremua betetzeko. Kasu honetan gutxieneko antzekotasun maila bat ezar daiteke parekatzea automatikoki txerta dadin. Horrez gain, aurrizki bat ezar daiteke txertatzea jada balidatu diren itzulpenetatik bereizteko.
Kontuz etiketekin
Sorburu fitxategiak izan ohi duen formatua normalean gorde egin behar izaten da helburu fitxategirako. Esaterako, webgune bat itzultzen ari bagara, beharbada gure bezeroak eskatu digu itzulitako fitxategiak ere formatu horretan eman behar dizkiogula.
OmegaT-k etiketak erabiltzen ditu fitxategien formatua erakusteko (ikus 5. irudia). Goian, berdez nabarmendurik, jatorrizko segmentua ageri da. Azpian itzulpena sartzeko edizio eremua dago.
5. irudia: Etiketadun testuaOmegaT-n

Etiketak hainbat karakterez (batetik hirura) eta zenbaki batez osaturik daude. HTML apur bat dakien edonork ikus dezake etiketa hauek HTML formatukoen antzekoak direla. Kontuz ibili behar da honekin: etiketa hauek ez dute testuaren formatu tipoa adierazten, adibidez etiketa pareak ez du zertan letra lodiaren ordezkari izan behar, HTMLan bezala.
Etiketen zenbakiak modu inkrementalean hazten dira etiketa taldeak sortu ahala. «Etiketa talde» deitzen dena etiketa bakarra izan daiteke (esaterako, ), edo bikote bat osatzen duten 2 etiketa (esaterako, eta ). Etiketa bakarrek inguruko testuan eraginik ez duen formatua adierazten dute: espazio hutsak, lerro jauziak... Etiketa bikoteek gehienetan estiloari buruzko informazioa adierazten dute, eta bikotearen hasierako etiketaren eta amaierako etiketaren artean dagoen testua formateatzen du. Bikote baten hasierako etiketak amaierako etiketaren aurretik geratu behar du beti.
Esan bezala, etiketek jatorrizko testuan dagoen formatu motaren bat ordezkatzen dute. Jatorrizko testuaren formatu ezaugarriak sinplifikatuz, etiketa kopurua txikiagoa izatea lortzen da. Posible bada, komenigarria da letra tipoak, letra tamainak, koloreak, etab. ahalik eta gehien bateratzea, itzulpena sinplifikatzeko eta balizko etiketa erroreak murrizteko. Etiketek traba gehiegi egiten badute eta formatuak garrantzi berezirik ez badauka egiten ari den lanerako, sorburu fitxategiko formatua kentzeak asko laguntzen du itzulpena errazago egiten.
Bestalde, etiketak ezabatu egin daitezke itzulpena egin ahala, jatorrizko testuaren formaturen bat ez dela gorde behar ikusten bada. Kasu horretan arreta berezia jarri behar da etiketa bikoteetan: bikotean, adibidez, bi etiketak ezabatu behar dira, haietakoren bat utziz gero dokumentuaren formatua hondatu egin baitaiteke.
OmegaT-k balidazio leiho bat dauka etiketak ondo daudela egiaztatzeko. Sorburu eta helburu segmentuetako etiketak bat datozen ala ez egiaztatzen du eta taula batean segmentu akastunak erakusten ditu. Segmentu bakoitzean klikatuz editorera joan gaitezke eta akatsa zuzendu.
Bilaketak
Askotan ez da aski izaten CAT aplikazioak egiten duen parekatzeen bilaketa automatikoa. Gerta daiteke itzuli nahi dugun testua glosarioetan ez egotea eta itzulpen memorietako parekatzeetan ez agertzea. Kasu horretan oso erabilgarria izaten da bilaketa sistema ahaltsua edukitzea (ikus 6. irudia).
6. irudia: Bilaketa leihoa
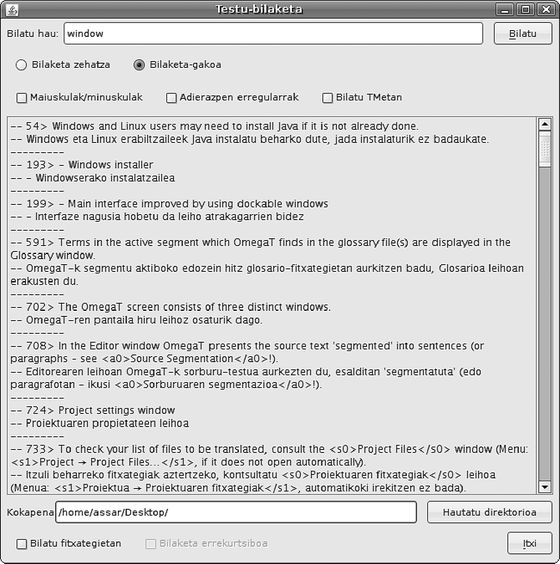
OmegaT-k abantaila pare bat dauka bilaketak egiteko orduan. Alde batetik, adierazpen erregularren eta komodinen erabilera onartzen du hitzak edo esaldiak bilatzeko, eta honek ikaragarrizko ahalmena ematen dio bilaketari. Bestetik, proiektu barruko dokumentuetan (sorburu fitxategietan, itzulpen memorietan, glosarioetan...) ageri diren testuak bilatzeaz gain, ordenagailuko edozein fitxategitan egin ditzake bilaketak, betiere fitxategiaren formatua OmegaT-k ulertzen duenetako bat bada.
Tresna lagungarriak
OmegaT-ren inguruan lan egiten duten garatzaileek itzultzaileentzako erabilgarriak izan daitezkeen beste aplikazio txiki batzuk ere garatu dituzte. Horietako zenbait OmegaT-n integratu dira denboran zehar, baina beste batzuk oraindik aplikazio independente gisa erabili behar dira. Garrantzitsuenak ondoko hauek dira:
- Aligner eta Bligner: lerrokatzaileak dira, hau da, jatorrizko hizkuntzan dagoen testu bat eta bere itzulpena edukirik, biak segmentatu, esanahi bera duten segmentuak parekatu eta itzulpen memoria bat sortzen duten aplikazioak.
- TMXMerger: TMX fitxategiak batzeko aplikazioa.
- TMXCleaner: TMX fitxategi bateko unitate «akastunak» (itzulpenik ez dutenak edo sorburua eta itzulpena berdina dutenak) ezabatzeko aplikazioa.
- Wordfast TMX file converter: Wordfastek sortzen dituen itzulpen memoriak moldatzen ditu OmegaT-k uler ditzan.
Garapena eta lokalizazioa
Esan bezala, aplikazio hau software librea da, eta kasu honetan ez dauka enpresa handien laguntzarik. Beraz, garapen lana boluntarioek egiten dute beren denbora librean. Garatzaileek webgune bat sortu dute software libreko aplikazio askoren biltegi den SourceForge gunean, nahi duen orok OmegaT-ren akatsen berri eman dezan, hobekuntzak eska ditzan edo, Javan programatzen dakienak, laguntza eskain dezan:
http://sourceforge.net/projects/omegat/
Horrez gain, OmegaT-ren erabiltzaileek foro bat daukate Interneten, aplikazioaren funtzionamenduari buruz eztabaidatu eta ezagutzak trukatzeko:
http://tech.groups.yahoo.com/group/OmegaT
OmegaT-ren interfazea eta dokumentazioa hainbat hizkuntzatan erabil daiteke. Itzulpen lan hau ere boluntarioek egiten dute. Euskarari dagokionez, hurrengo bertsiotik aurrera interfazea behintzat euskaraz egotea espero da. OmegaT erabiltzera animatzen bazarete eta lokalizazioan akatsen bat aurkitzen baduzue, mesedez eman haren berri euskararen lokalizazioaren arduradunari, arestian aipatu den web helbidean.


